|
LLM for Unity
v2.5.2
Create characters in Unity with LLMs!
|
|
LLM for Unity
v2.5.2
Create characters in Unity with LLMs!
|
![]()

![]()
![]()

![]()
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine.
It allows to create intelligent characters that your players can interact with for an immersive experience.
The package also features a Retrieval-Augmented Generation (RAG) system that allows to performs semantic search across your data, which can be used to enhance the character's knowledge. LLM for Unity is built on top of the awesome llama.cpp library.
🧪 Tested on Unity: 2021 LTS, 2022 LTS, 2023, Unity 6
🚦 Upcoming Releases
 this work to allow even cooler features!
this work to allow even cooler features!Contact us to add your project!
Method 1: Install using the asset store
Add to My AssetsWindow > Package ManagerPackages: My Assets option from the drop-downLLM for Unity package, click Download and then ImportMethod 2: Install using the GitHub repo:
Window > Package Manager+ button and select Add package from git URLhttps://github.com/undreamai/LLMUnity.git and click Add
First you will setup the LLM for your game 🏎:
Add Component and select the LLM script.Download Model button (~GBs).Load model button (see LLM model management).Then you can setup each of your characters as follows 🙋♀️:
Add Component and select the LLMCharacter script.Prompt. You can define the name of the AI (AI Name) and the player (Player Name).LLM field if you have more than one LLM GameObjects.You can also adjust the LLM and character settings according to your preference (see Options).
In your script you can then use it as follows 🦄:
You can also specify a function to call when the model reply has been completed.
This is useful if the Stream option is enabled for continuous output from the model (default behaviour):
To stop the chat without waiting for its completion you can use:
That's all ✨!
You can also:
For mobile apps you can use models with up to 1-2 billion parameters ("Tiny models" in the LLM model manager).
Larger models will typically not work due to the limited mobile hardware.
iOS iOS can be built with the default player settings.
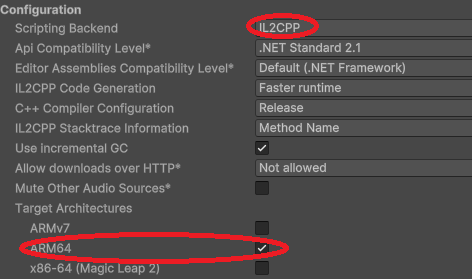
Android On Android you need to specify the IL2CPP scripting backend and the ARM64 as the target architecture in the player settings.
These settings can be accessed from the Edit > Project Settings menu within the Player > Other Settings section.
Since mobile app sizes are typically small, you can download the LLM models the first time the app launches. This functionality can be enabled with the Download on Build option. In your project you can wait until the model download is complete with:
You can also receive calls during the download with the download progress:
This is useful to present a progress bar or something similar. The MobileDemo is an example application for Android / iOS.
To restrict the output of the LLM you can use a grammar, read more here.
The grammar can be saved in a .gbnf file and loaded at the LLMCharacter with the Load Grammar button (Advanced options).
For instance to receive replies in json format you can use the json.gbnf grammar.
Graamars in JSON schema format are also supported and can be loaded with the Load JSON Grammar button (Advanced options).
Alternatively you can set the grammar directly with code:
For function calling you can define similarly a grammar that allows only the function names as output, and then call the respective function.
You can look into the FunctionCalling sample for an example implementation.
The chat history of a LLMCharacter is retained in the chat variable that is a list of ChatMessage objects.
The ChatMessage is a struct that defines the role of the message and the content.
The first element of the list is always the system prompt and then alternating messages with the player prompt and the AI reply.
You can modify the chat history directly in this list.
To automatically save / load your chat history, you can specify the Save parameter of the LLMCharacter to the filename (or relative path) of your choice. The file is saved in the persistentDataPath folder of Unity. This also saves the state of the LLM which means that the previously cached prompt does not need to be recomputed.
To manually save your chat history, you can use:
and to load the history:
where filename the filename or relative path of your choice.
The last argument of the Chat function is a boolean that specifies whether to add the message to the history (default: true):
For this you can use the async/await functionality:
You can use a remote server to carry out the processing and implement characters that interact with it.
Create the server
To create the server:
LLM script as described aboveRemote option of the LLM and optionally configure the server parameters: port, API key, SSL certificate, SSL keyAlternatively you can use a server binary for easier deployment:
windows-cuda-cu12.2.0.In both cases you'll need to enable 'Allow Downloads Over HTTP' in the project settings.
Create the characters
Create a second project with the game characters using the LLMCharacter script as described above. Enable the Remote option and configure the host with the IP address (starting with "http://") and port of the server.
The Embeddings function can be used to obtain the emdeddings of a phrase:
A detailed documentation on function level can be found here: ![]()
LLM for Unity implements a super-fast similarity search functionality with a Retrieval-Augmented Generation (RAG) system.
It is based on the LLM functionality, and the Approximate Nearest Neighbors (ANN) search from the usearch library.
Semantic search works as follows.
Building the data You provide text inputs (a phrase, paragraph, document) to add to the data.
Each input is split into chunks (optional) and encoded into embeddings with a LLM.
Searching You can then search for a query text input.
The input is again encoded and the most similar text inputs or chunks in the data are retrieved.
To use semantic serch:
Add Component and select the RAG script.SimpleSearch is a simple brute-force search, whileDBSearch is a fast ANN method that should be preferred in most cases.Alternatively, you can create the RAG from code (where llm is your LLM):
In your script you can then use it as follows :unicorn::
You can also add / search text inputs for groups of data e.g. for a specific character or scene:
{.cs} rag.Save("rag.zip");
{.cs} await rag.Load("rag.zip");
{.cs} string message = "How is the weather?"; (string[] similarPhrases, float[] distances) = await rag.Search(message, 3);
string prompt = "Answer the user query based on the provided data. "; prompt += $"User query: {message} "; prompt += $"Data: "; foreach (string similarPhrase in similarPhrases) prompt += $" - {similarPhrase}";
_ = llmCharacter.Chat(prompt, HandleReply, ReplyCompleted); ```
The RAG sample includes an example RAG implementation as well as an example RAG-LLM integration.
That's all :sparkles:!
LLM for Unity uses a model manager that allows to load or download LLMs and ship them directly in your game.
The model manager can be found as part of the LLM GameObject:
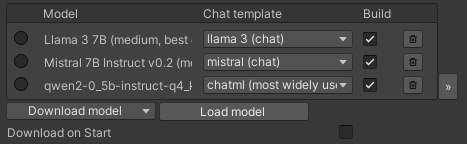
You can download models with the Download model button.
LLM for Unity includes different state of the art models built-in for different model sizes, quantised with the Q4_K_M method.
Alternative models can be downloaded from HuggingFace in the .gguf format.
You can download a model locally and load it with the Load model button, or copy the URL in the Download model > Custom URL field to directly download it.
If a HuggingFace model does not provide a gguf file, it can be converted to gguf with this online converter.
The chat template used for constructing the prompts is determined automatically from the model (if a relevant entry exists) or the model name.
If incorrecly identified, you can select another template from the chat template dropdown.
Models added in the model manager are copied to the game during the building process.
You can omit a model from being built in by deselecting the "Build" checkbox.
To remove the model (but not delete it from disk) you can click the bin button.
The the path and URL (if downloaded) of each added model is diplayed in the expanded view of the model manager access with the >> button:

You can create lighter builds by selecting the Download on Build option.
Using this option the models will be downloaded the first time the game starts instead of copied in the build.
If you have loaded a model locally you need to set its URL through the expanded view, otherwise it will be copied in the build.
❕ Before using any model make sure you check their license ❕
The Samples~ folder contains several examples of interaction 🤖:
To install a sample:
Window > Package ManagerLLM for Unity Package. From the Samples Tab, click Import next to the sample you want to install.The samples can be run with the Scene.unity scene they contain inside their folder.
In the scene, select the LLM GameObject and click the Download Model button to download a default model or Load model to load your own model (see LLM model management).
Save the scene, run and enjoy!
Details on the different parameters are provided as Unity Tooltips. Previous documentation can be found here (deprecated).
The license of LLM for Unity is MIT (LICENSE.md) and uses third-party software with MIT and Apache licenses. Some models included in the asset define their own license terms, please review them before using each model. Third-party licenses can be found in the (Third Party Notices.md).